What is Map-Reduce(Hadoop) Programming?
I hope you all having a great summer. It's a cool-summer here in Silicon Valley.
I am sure by this time you came across "map-reduce programming" or at-least "Hadoop" framework. If not, do yourself a favor- search on Google for Hadoop. I also have an introduction about Hadoop here.
The "map-reduce" is the fundamental algorithm in the Hadoop framework for processing big-data. I came across a very simple explanation in one of the presentation and this is mostly self-explanatory.
Pl take a look at this picture below:
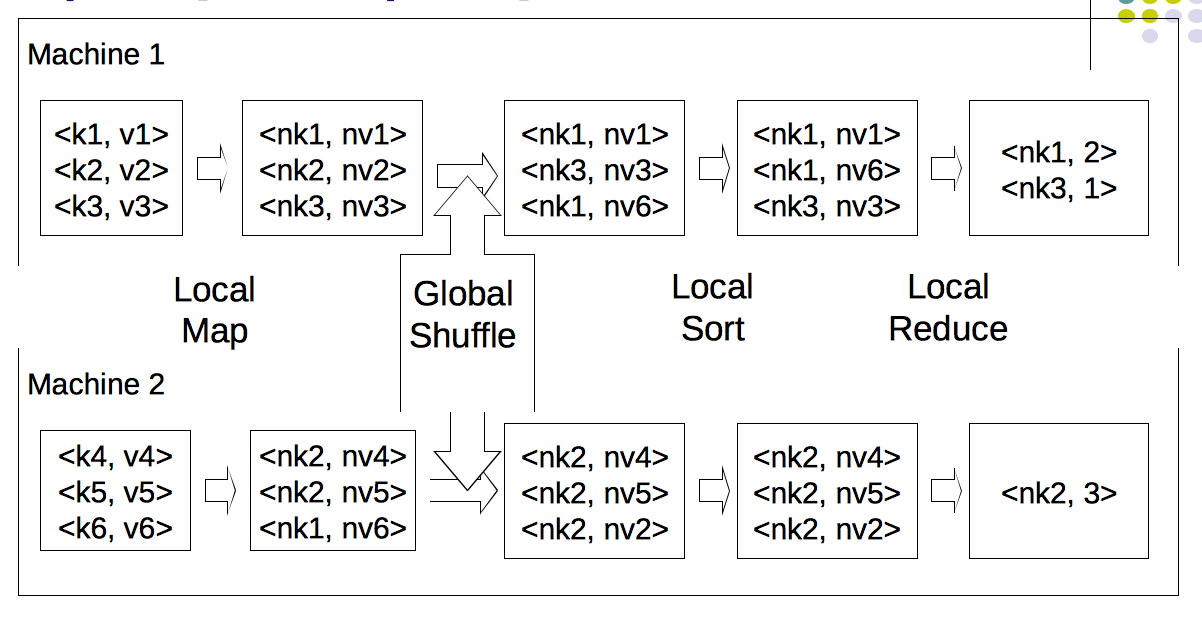
There are 2 machines which has big-data. It's mapped into key-value pair. Then do a map at the local machines.
Next step is the merging of these separate sets of key-value pair. This step involves global shuffle and followed by local sort. Then it make sense to remove the duplicate keys at the local machines. The result is ready for processing by HDFS. This is the 1st part of Hadoop processing of big data. The next & last step is the actual processing of data in HDFS. HDFS is an interesting user-level distributed file system. I will explain about the internals of HDFS in my next blog. The complete Hadoop framework is written in Java.
posted by Uday Subbarayan @ 8:42 AM
1 comments
![]()
![]()

